Building a Fast REST API with Robyn and Cockroach DB | Python

I am a backend developer from Venezuela. I enjoy writing tutorials for open source projects I using and find interesting. Mostly I write tutorials about Python, Go, and Rust.
This article is aimed at developers who want to learn how to build a REST API with Robyn, a fast async Python web framework coupled with a web server written in Rust, and Cockroach DB, a distributed SQL database that provides ACID transactions and automatic data replication. The article provides a step-by-step guide on how to create a table, insert data into the table, and perform CRUD operations. The author also explains the functions and endpoints used in the project and provides references to other resources that can be helpful for developers.
Requirements
Python knowledge
Basic SQL knowledge
Robyn
Robyn is a fast async Python web framework coupled with a web server written in Rust.
CockroachDB
According to its Github's page:
CockroachDB is a distributed SQL database built on a transactional and strongly-consistent key-value store. It scales horizontally; survives disk, machine, rack, and even data center failures with minimal latency disruption and no manual intervention; supports strongly-consistent ACID transactions; and provides a familiar SQL API for structuring, manipulating, and querying data.
CockroachDB has support for Python using Psycopg, SQLAlchemy, Django ORM, Pony ORM.
For this tutorial, we are going to use the Psycopg2 driver, to connect to a CockroachDB cluster.
Psycopg2
Psycopg is the most popular PostgreSQL database adapter for the Python programming language. Its main features are the complete implementation of the Python DB API 2.0 specification and the thread safety (several threads can share the same connection). It was designed for heavily multi-threaded applications that create and destroy lots of cursors and make a large number of concurrent INSERTs or UPDATEs.
Installation
pip install robyn psycopg2-binary python-dotenv
Creating a CockroachDB Cluster
We have to have a CockroachDB account and create a cluster. You can sign in here.
After we create a cluster. We press on Connect.
Then, we select Python in the language field and Psycopg2 in the tool field.
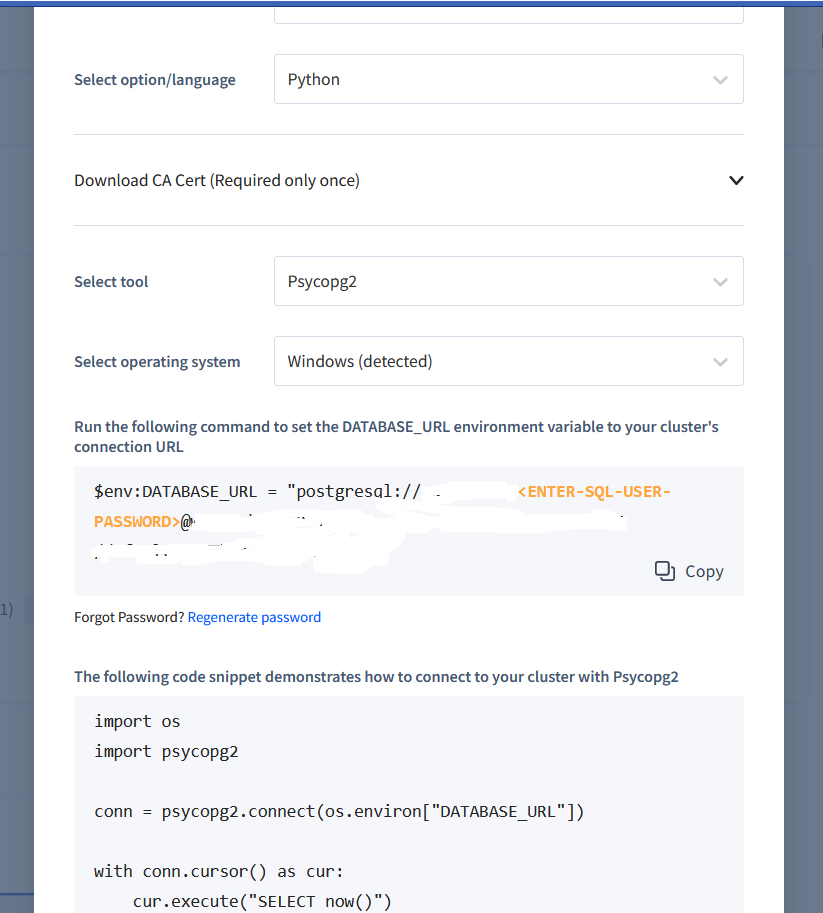
We copy the DATABASE_URL, which is the connection URL. Through this URL we connect our app to the cluster.
When we create a new cluster, we have to download a CA certificate. CockroachDB shows us a URL we have to copy and paste into our command line or PowerShell on Windows, to download the certificate.
The URL has the form:
mkdir -p $env:appdata\postgresql\; Invoke-WebRequest -Uri https://cockroachlabs.cloud/clusters/<Strings>/cert -OutFile $env:appdata\postgresql\root.crt
Project Structure
robyn-postgres-demo/
app.py
controllers.py
helpers.py
init_db.py
Creating a table
init_db.py
import os
import psycopg2
from dotenv import load_dotenv
load_dotenv()
DATABASE_URL = os.getenv('DATABASE_URL')
conn = psycopg2.connect(
DATABASE_URL
)
cur = conn.cursor()
cur.execute('DROP TABLE IF EXISTS books;')
cur.execute('CREATE TABLE books (id serial PRIMARY KEY,'
'title varchar (150) NOT NULL,'
'author varchar (50) NOT NULL,'
'date_added date DEFAULT CURRENT_TIMESTAMP);'
)
Inside the init_db.py file, we load the DATABASE_URL as environment variables to get access to the CockroachDB cluster. Then, we initialize a cursor to perform database operations. And create a table named books.
Inserting data into the table
init_db.py
cur.execute('INSERT INTO books (title, author)'
'VALUES (%s, %s)',
('A Tale of Two Cities',
'Charles Dickens')
)
conn.commit()
cur.close()
conn.close()
The code above inserts data every time we start the server.
controllers.py
from init_db import get_db_connection
def all_books():
conn = get_db_connection()
cur = conn.cursor()
cur.execute('SELECT * FROM books;')
books = cur.fetchall()
cur.close()
conn.close()
return books
This function retrieves all the rows in the database.
app.py
We create a new file app.py to write our endpoints. We will start writing an endpoint to retrieve all the rows in the database.
from robyn import Robyn
from controllers import all_books
app = Robyn(__file__)
@app.get("/books")
async def books():
books = all_books()
return {"status_code":200, "body": books, "type": "json"}
app.start(port=8000, url="0.0.0.0")
The all_books() function retrieves all the rows in the database. But, it returns them as a list of tuples. We need the function to return a list of JSON.
[(845070245202624513, 'A Tale of Two Cities', 'Charles Dickens', datetime.date(2023, 2, 22)), (845070245202624514, 'Anna Karenina', 'Leo Tolstoy', datetime.date(2023, 2, 22))]
We have to create a file with helpers, to transform data into dictionaries so the endpoints can return data as JSON.
helpers.py
def to_dict(psycopg_tuple:tuple):
book_dict = collections.OrderedDict()
book_dict['id'] = psycopg_tuple[0]
book_dict['title'] = psycopg_tuple[1]
book_dict['author'] = psycopg_tuple[2]
book_dict['datetime'] = psycopg_tuple[3].strftime("%m/%d/%Y")
return book_dict
def list_dict(rows:list):
row_list = []
for row in rows:
book_dict = to_dict(row)
row_list.append(book_dict)
return row_list
The to_dict() function has a tuple as a parameter. And transforms it into an ordered dictionary, this way the position of the key-value pairs will not change.
The list_dict() function has a list as a parameter. We use it to convert a list of tuples to a list of dictionaries.
Controllers
In controllers.py we are going to write all the functions to perform CRUD operations.
All the records
def all_books():
conn = get_db_connection()
cur = conn.cursor()
cur.execute('SELECT * FROM books;')
books = list_dict(cur.fetchall())
cur.close()
conn.close()
return books
The all_books() function retrieves all the records in the database.
Creating a record
def new_book(title:str, author:str):
conn = get_db_connection()
cur = conn.cursor()
cur.execute('INSERT INTO books (title, author)'
'VALUES (%s, %s) RETURNING *;',
(title, author))
book = cur.fetchone()[:]
book_dict = to_dict(book)
conn.commit()
cur.close()
conn.close()
return json.dumps(book_dict)
The new_book() function has title and author as parameters and insert the values into the database. Then retrieves the last row added, convert it to a dictionary and returns it as JSON.
Retrieving by ID
def book_by_id(id:int):
conn = get_db_connection()
cur = conn.cursor()
try:
cur.execute('SELECT * FROM books WHERE id=%s', (id,))
book = cur.fetchone()
book_dict = to_dict(book)
cur.close()
conn.close()
return json.dumps(book_dict)
except:
return None
book_by_id() function has id as a parameter. With this function, we retrieve a row by its ID and return it as JSON. If there is no row with the ID passed, the function returns None.
Updating a record
def update_book(title:str, author, pages_num, review, id:int):
conn = get_db_connection()
cur = conn.cursor()
cur.execute('UPDATE books SET title = %s, author=%s WHERE id = %s RETURNING *;', (title, author, id))
book = cur.fetchone()[:]
book_dict = to_dict(book)
conn.commit()
cur.close()
conn.close()
return json.dumps(book_dict)
We use update_book() controller to update the values of a row. The function returns JSON with the row updated.
Deleting a record
def delete_book(id:int):
conn = get_db_connection()
cursor = conn.cursor()
cursor.execute("DELETE FROM books WHERE id = %s", (id,))
conn.commit()
conn.close()
return "Book deleted"
We pass an ID of a row to delete_book, to delete the row.
Endpoints
On app.py file we import all the functions from controllers.py. And write all the endpoints.
POST endpoints
from robyn import Robyn
from controllers import all_books, new_book, book_by_id, delete_book, update_book
import json
app = Robyn(__file__)
@app.post("/book")
async def create_book(request):
body = bytearray(request['body']).decode("utf-8")
json_body = json.loads(body)
try:
book = new_book(json_body['title'], json_body['author'])
return {"status_code":201, "body": book, "type": "json"}
except:
return {"status_code":500, "body": "Internal Server Error", "type": "text"}
app.start(port=8000, url="0.0.0.0")
This endpoint creates a new row. The function extracts the body from the request and converts it to JSON. Then, It passes the values to new_book() function and returns 201 as the status code, and the row that was created as the body.
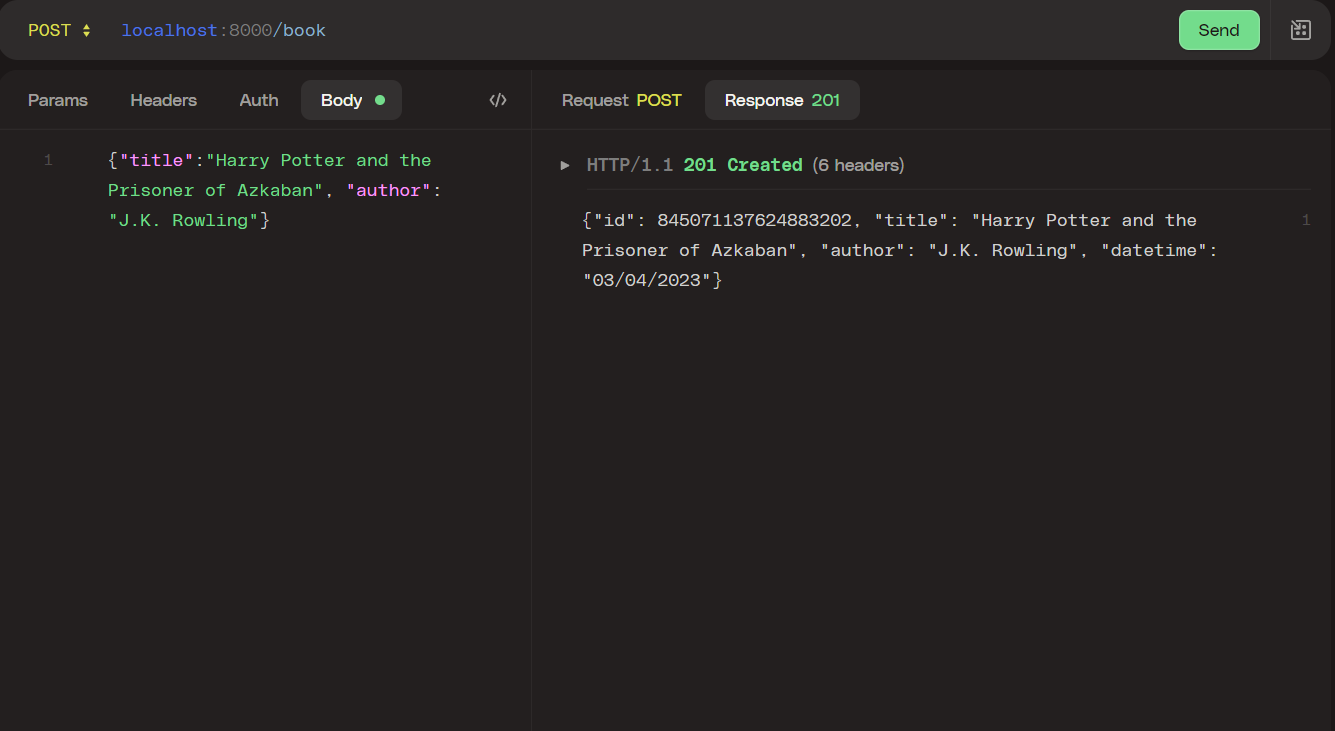
If we use an HTTP client and go to localhost:8000/book and send the following body: {"tittle":"Harry Potter and the Prisoner of Azkaban", "author":"J.K. Rowling"} . We should see a response like this:
GET endpoints
@app.get("/books")
async def books():
books = all_books()
return books
This endpoint executes all_books() function to return all the rows in the database.
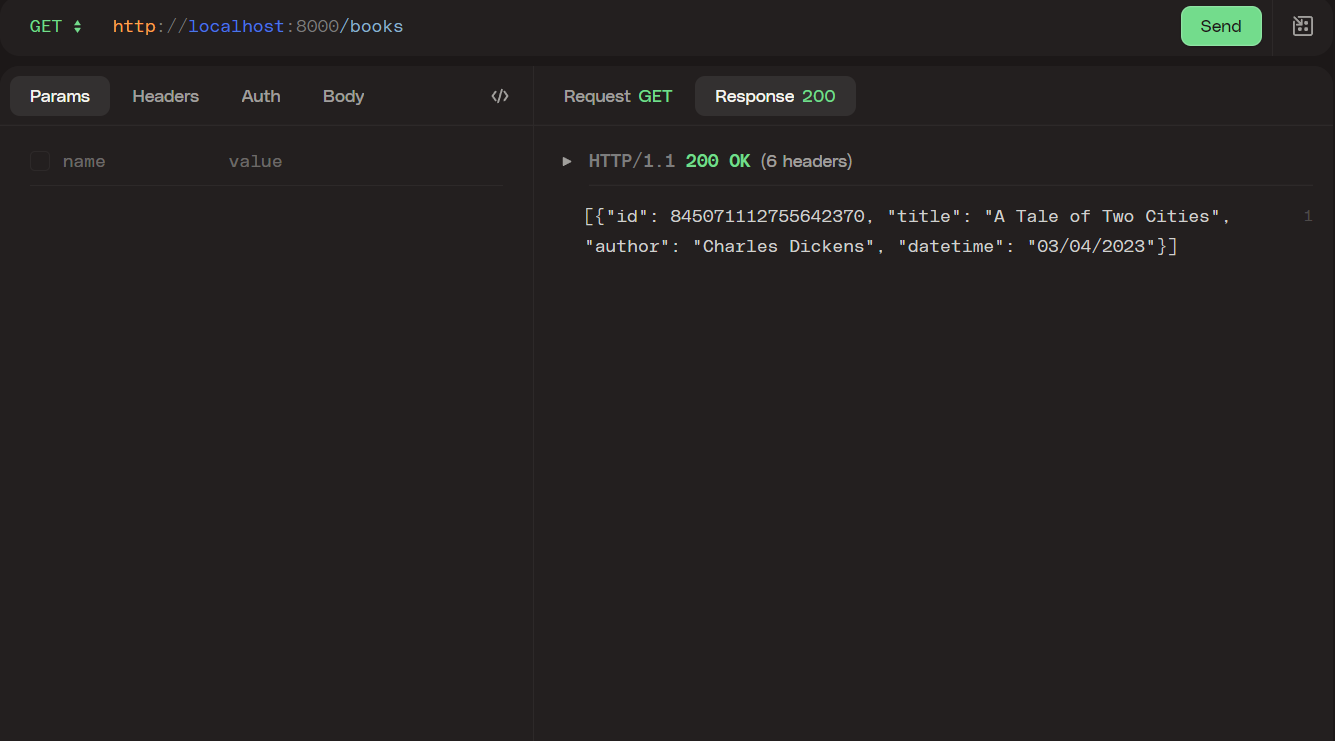
If we go to localhost:books, we should see a response like this:
@app.get("/book/:id")
async def get_book(request):
id = request['params']['id']
book = book_by_id(id)
try:
if book == None:
return {"status_code":404, "body": "Book not Found", "type": "text"}
else:
return {"status_code":200, "body": book, "type": "json"}
except:
return {"status_code":500, "body": "Internal Server Error", "type": "text"}
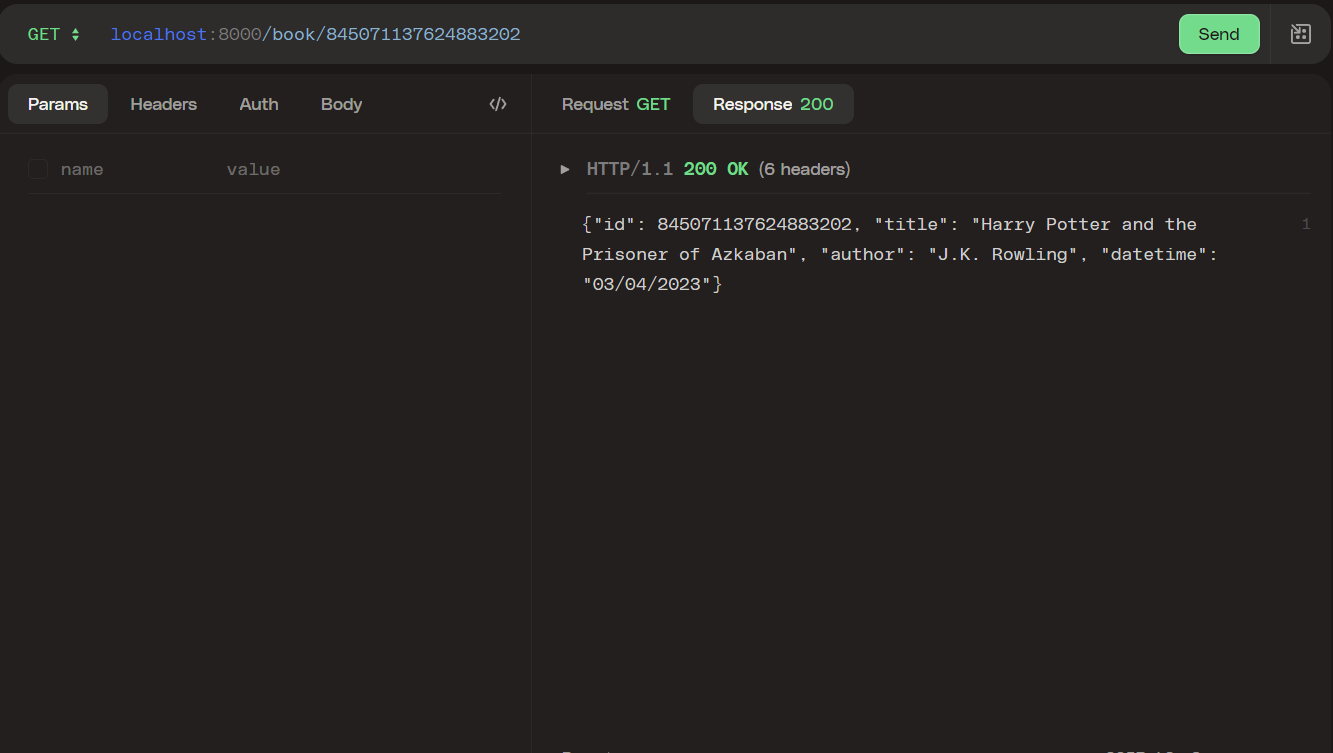
This endpoint extracts the ID parameter from the request and passes it to the book_by_id() function if the search succeeds, it returns a status code 200 and the row as the body. If no book matches the ID passed, it will return a status code 404 and the message "Book not found" as a response.
When we go to localhost:8000/book/:id we should have a response like this:
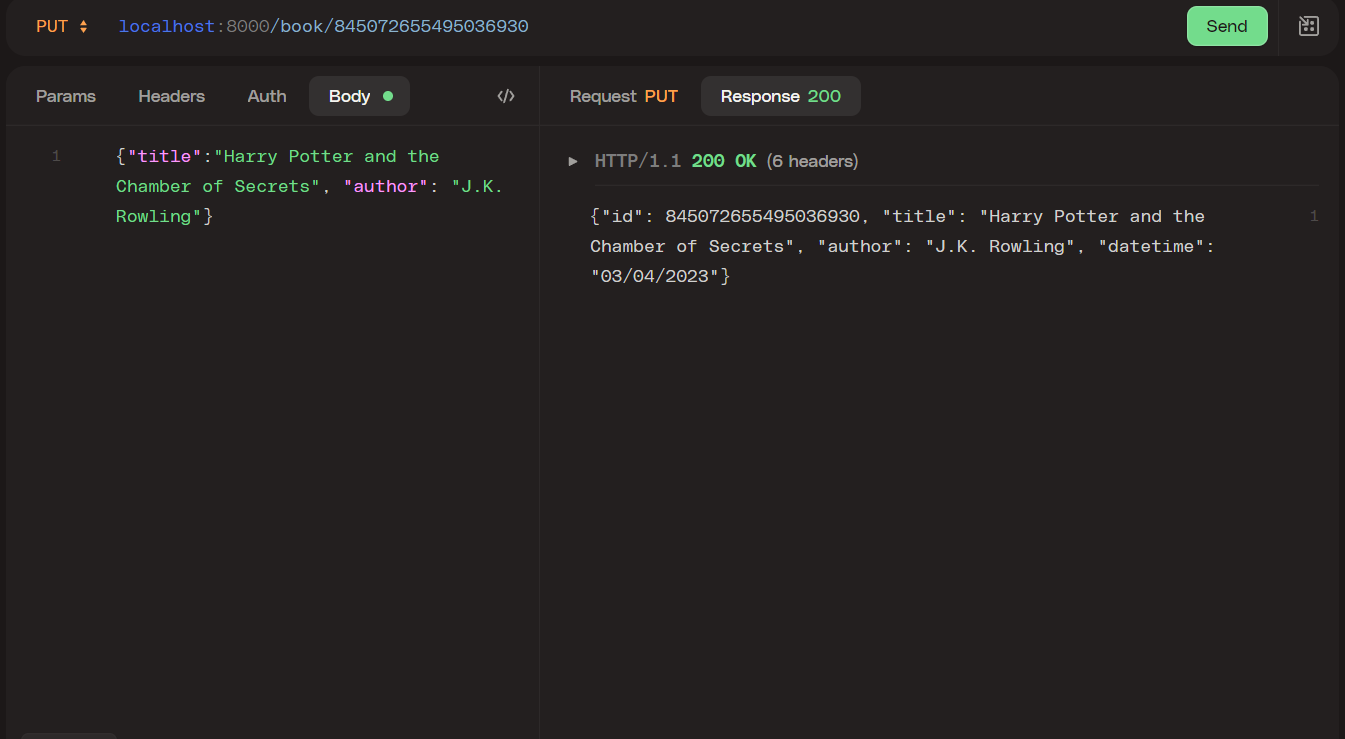
PUT endpoint
@app.put("/book/:id")
async def update(request):
id = request['params']['id']
body = bytearray(request['body']).decode("utf-8")
json_body = json.loads(body)
title = json_body['title']
author = json_body['author']
book_id = book_by_id(id)
if book_id == None:
return {"status_code":404, "body": "Book not Found", "type": "text"}
else:
try:
book = update_book(title, author, id)
return {"status_code":200, "body": book, "type": "json"}
except:
return {"status_code":500, "body": "Internal Server Error", "type": "text"}
First, this function searches that the ID passed matches one in the database. Then, it proceeds to pass the values to the update_book() function and update the row. If the operation succeeds, it will return a status code 200 and the updated row as a response.
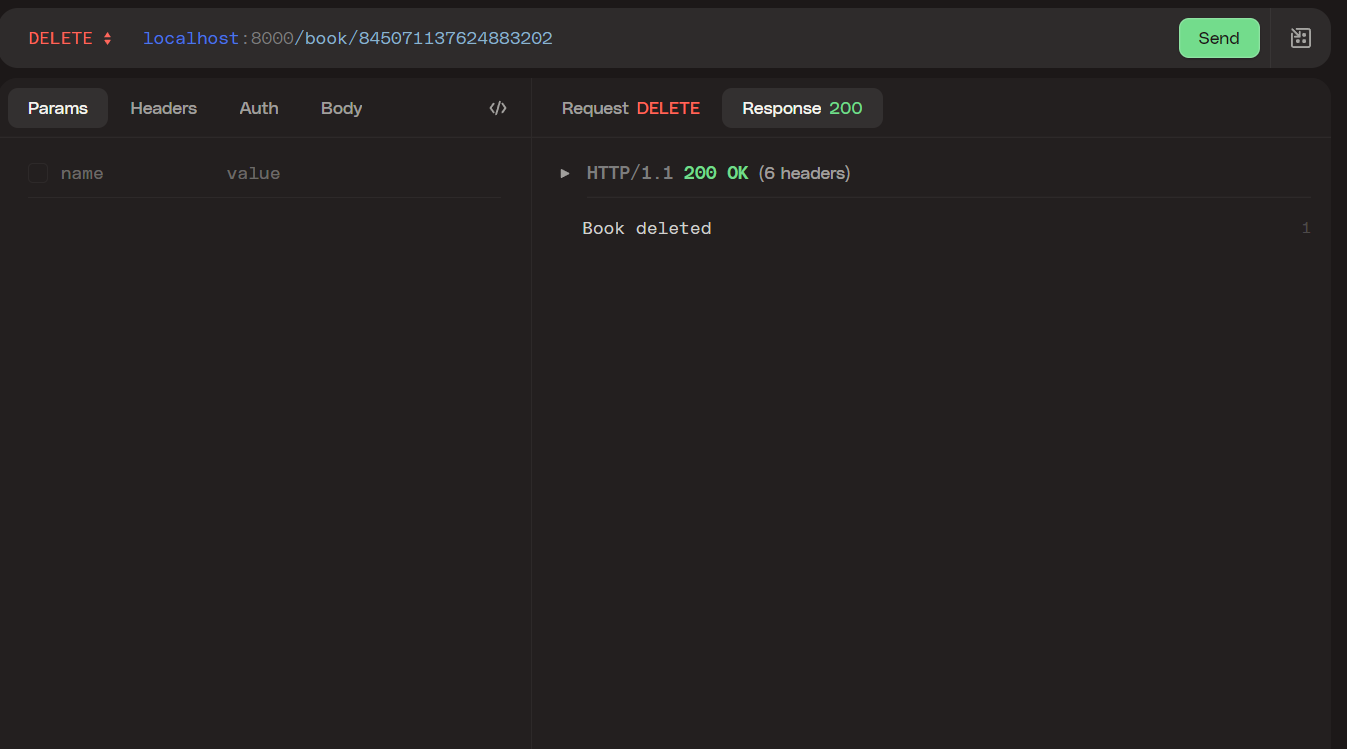
DELETE endpoint
@app.delete("/book/:id")
async def delete(request):
id = request['params']['id']
book_id = book_by_id(id)
if book_id == None:
return {"status_code":404, "body": "Book not Found", "type": "text"}
else:
try:
delete_book(id)
return {"status_code":200, "body": "Book deleted", "type": "json"}
except:
return {"status_code":500, "body": "Internal Server Error", "type": "text"}
app.start(port=8000, url="0.0.0.0")
In this endpoint, the function extracts the ID parameter, then it looks for the row in the database. Then passes the ID to the delete_book() function to delete the row.
Conclusion
In conclusion, I write this article to provide a guide on how to build a fast REST API with Robyn and Cockroach DB using Python. The article covers the basics of Robyn, CockroachDB, and Psycopg2, and provides step-by-step instructions on how to create a table, insert data into the table, and perform CRUD operations. The article also includes information on the project structure, creating endpoints, and controllers. Overall, this article is a resource for developers who want to learn how to build a REST API with Robyn and Cockroach DB using Python.
Thank you for taking the time to read this article.
If you have any recommendations about other packages, architectures, how to improve my code, my English, or anything; please leave a comment or contact me through Twitter, or LinkedIn.
The source code is here.




